今回のお題はユーザの多いストキャスティクスを。直近の一定期間における値幅(最高値-最安値)中の終値相対位置を元に、「売られ過ぎ・買われ過ぎ」を表現するオシレータ指標です。詳細は下記を参照下さい。
計算に使う株価データは毎度お馴染み、日経平均プロフィルさんから。CSV ファイルを読み出して Pandas データフレームに格納する処理のコードはシリーズ第1回目を参照ください。
指標のなかでは比較的計算が面倒な部類かと想いますが、pandas のパワフルな集計機能のおかげで関数ひとつに纏められました。尚、%K・%D・Slow%D はいずれも単位が[%]として使われるのが一般的ですが、データフレームには生の値を格納しておき、視覚化の際にパーセント値に補正するというのは個人的な嗜好ですw
# ストキャスティクス計算(%K, %D, Slow%D を返す) def calc_stochastic(close, high, low, length): # 期間内の最高値・最安値 highest = high.rolling(length).max() lowest = low.rolling(length).min() # 終値 - 最安値 d = close - lowest # 最高値 - 最安値 n = highest - lowest # %K pc_k = d / n # %D pc_d = d.rolling(3).sum() / n.rolling(3).sum() # Slow%D slow_pc_d = pc_d.rolling(3).mean() return pc_k, pc_d, slow_pc_d # ストキャスティクス計算期間[日] STOCHASTIC_DAYS = 9 # ストキャスティクスを計算してデータフレーム列に加える df['pc_k'], df['pc_d'], df['slow_pc_d'] = calc_stochastic(df.close, df.high, df.low, STOCHASTIC_DAYS)
という訳で、いつものように日足と上下段で見える化を。
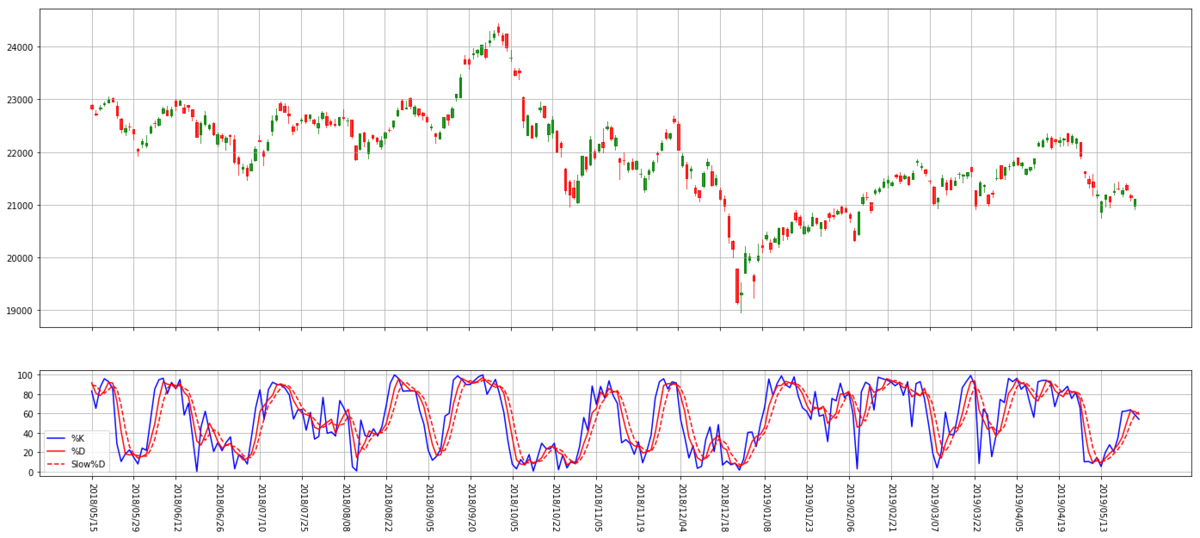
指標の使い方や評価にまで踏み込んでしまうとエンドレスになりそうなので、それはまたの機会に。今回もコード一式と実行結果は Google Colaboratory でどうぞ↓。